* 인공 신경망과 관련이 있다.
목차
분류 (classification)
인공 뉴런 (Artificial Neuron)
인공 뉴런의 연결
인경신경망의 분류
인공신경망의 학습
객체 지향 프로그래밍 (Object Oriented Programming)
상속 (Inheritance)
numpy
1. 분류
어떤 클래스를 가지고 있는 것을 분류하는 것 ex. 개? 고양이? 이 사진은 개일까? 고양이일까?
클래스(ex.개, 고양이)가 정해져있고 input이 어디에 속하는지 판단
클래스는 두개일 수도있고 많을 수도 있다.

이 함수를 만들어내는 것을 분류 문제이다.
컴퓨터는 오직 0,1로 구성되어있기때문에 개와 고양이를 어떤 숫자에 대응시켜야한다.
ex. 개(1,0) 고양이 (0,1)
텐서값을 입력으로 받아서 (1,0)또는 (0,1)이 나오게끔 만드는 것이 분류이다.
* 정확도:
100개를 넣어서 98개가 맞았다 -> 98% 정확도
즉, 분류문제는 어떤 클래스에 속하는 것을 찾아낼 수 있느냐 없느냐. 정확도는 맞추었느냐.
이런 분류 문제를 인공신경망으로 어떻게 해결할까?
2. 인공신경망(인공 뉴런)
- McCulloch and pitts [맥컬럭과 피츠] 라는 사람이 1960년대에 만들었다.
외부에서 신경이 오면 합쳐지고, Threshold를 넘으면 다음 뉴런으로 넘어간다.
기본 구조:
입력값이 들어오면 더해지고, 어떤 역치를 넘는지 판단하여, 넘는경우에 활성화가 되어, 다른 뉴런에 전달한다.
이런 것들이 여러개가 되어 분류문제를 해결한다.
- 하나로는 아무것도 할 수 없다.
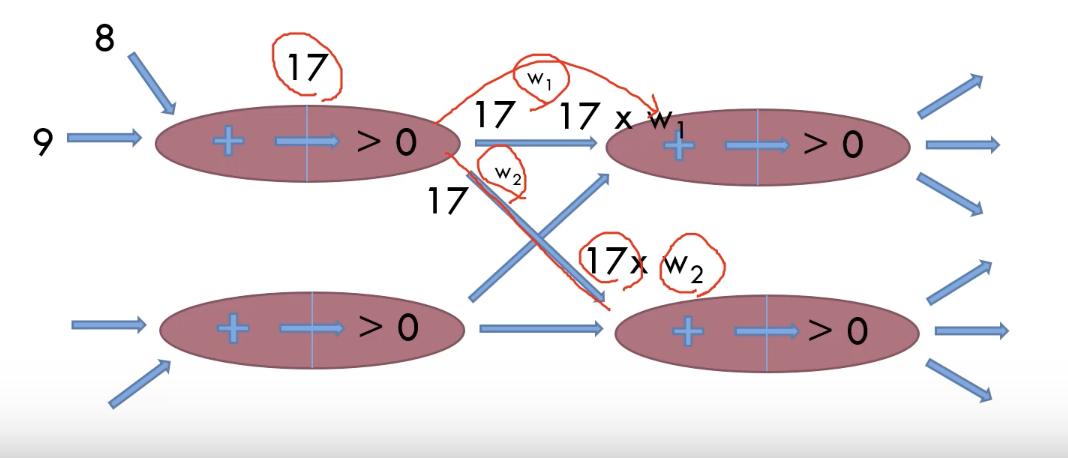
2. 인공신경망(인공 뉴런)의 연결
-> 2개의 층에 4개의 뉴런이 연결
뉴런과 뉴런이 연결되는 부분이 시냅스이다. (파란색 화살표)
그리고 우리는 가중치라고 부른다. 그리고 이는 곱해진다. (W값이 곱해짐)
3. 인공신경망(인공 뉴런)의 분류
분류란? 입력값이 있고 그에 따른 출력이 어떠한 클래스에 포함되는지를 판단해준다.
y1(1,0)에서 클래스가 2가지구나, 1번째에 해당되는구나 알 수 있음.
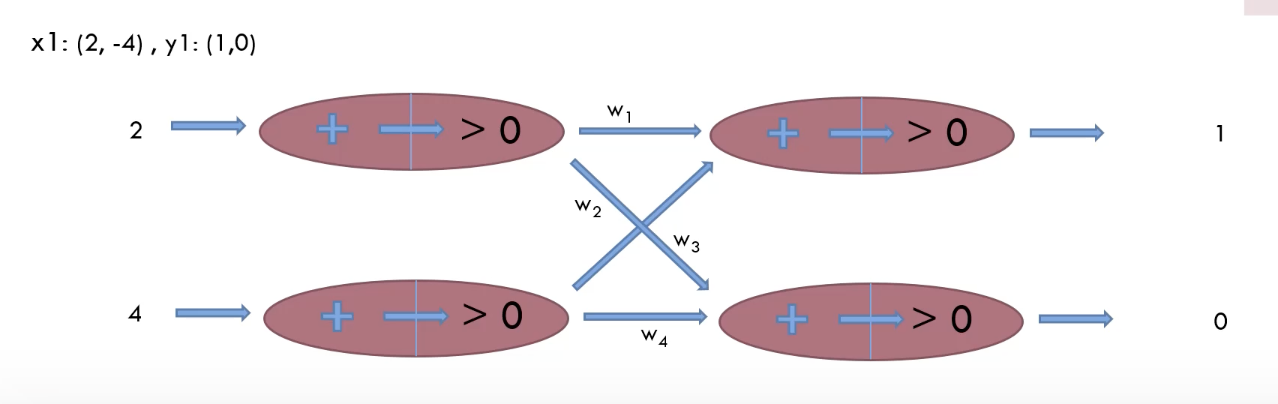
여기서 우리가 원하는 것, 2,-4를 넣어서 더해서 가중치를 곱하면 출력값이 1,0과 가깝게하자

출력이 2,-5가 나오면? 우리는 맞았다고 판단한다. (2가 -5보다 크니까) 2,5면 틀림
결론) 인공신경망을 이용한 분류란?
입력값을 넣고 값을 처리해서 나온 결과고 우리가 원하는 결과가 나올 때 분류를 할 수 있다고 이야기한다.
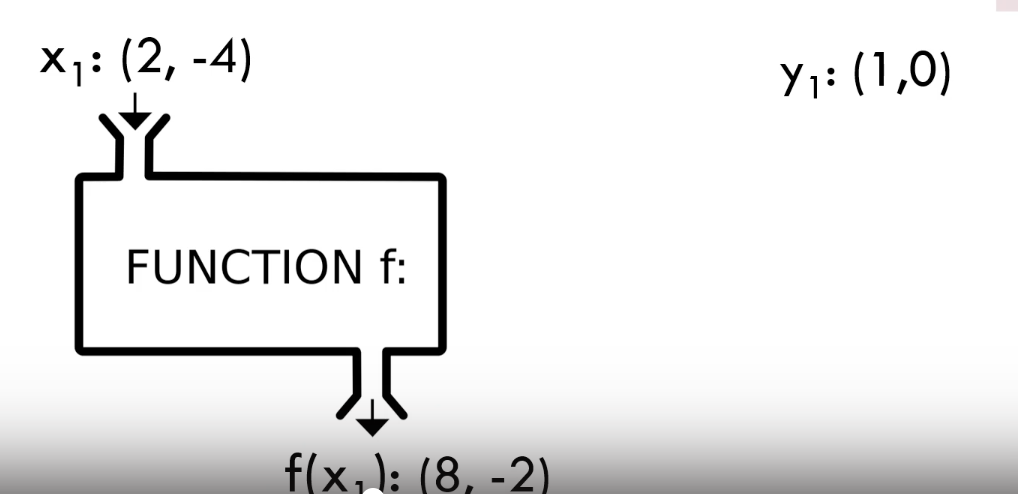
우리는 결과가 1,0이기 때문에 f(x1)의 결과가 8>-2이길 원한다.
4. 인공신경망(인공 뉴런)의 학습
우리는 Y1(1,0)과 f(x1): (8,-2)의 거리가 작아지도록 학습시키고싶다.
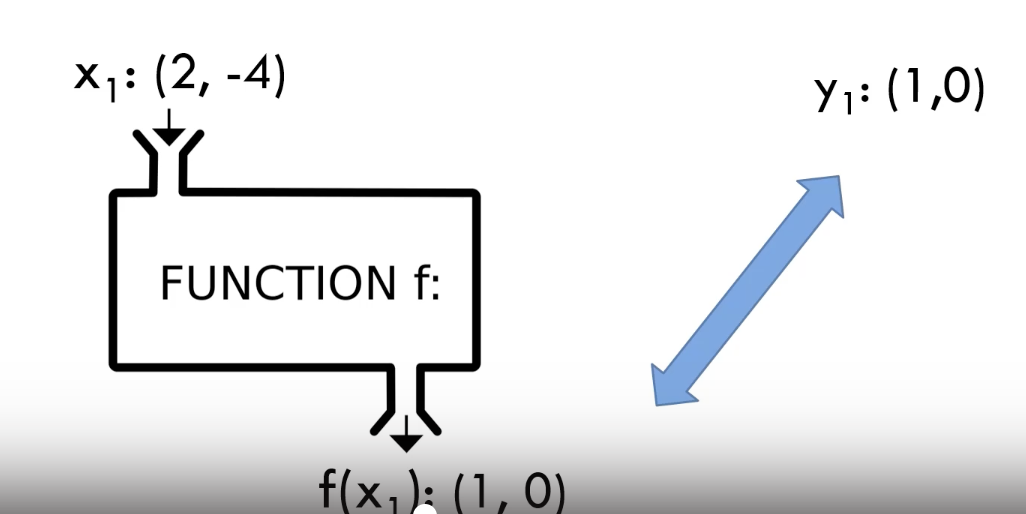
이렇게!
Loss function을 정의한다.
f(x) ~ y가 얼마나 가까운지 판단. ex. f(x1): (8,-2) ~ y1(1,0)
문제 1) scale이 안맞다(양수와 음수)
해결: softmax 함수

-> soft max 함수
결과를 확률로 해석할 수 있게 변환해주는 함수이다. 이는 결과값을 정규화시키는 것으로 볼 수도 있다.
입력받은 값을 출력으로 0~1 사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 된다.
위 함수에서 j는 클래스 수를 나타내고, ai는 소프트맥스 함수의 입력값으로 볼 수 있다. 즉 직관적으로 해석해보면 i번째 입력값 / 입력값의 합 으로 볼 수 있다.
(지수 함수가 사용되는 이유는 미분이 가능하게 하면서, 입력값 중 큰 값은 더 크게, 작은 값은 더 작게 만들 수 있다.)
참고)
https://syj9700.tistory.com/38
문제 2) 어떻게 가까운지 판단하지?
해결: Root Mean Square Deviation? or Cross Entropy
(MSE는 회귀에서, CEE는 분류에서 소프트맥스 함수의 손실함수로 사용된다. )
-> Cross Entropy loss (즉 크로스 엔트로피 손실)은 머신 러닝의 분류 모델이 얼마나 잘 수행되는지 측정하기 위해 사용되는 지표이다. 머신러닝에서 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포 사이의 차이를 나타낸다.
loss가 0일 때 완벽한 모댈로 0에 가깝게 만드는 것이 목표이다.
데이터가 연속된 값을 가지는 회귀 문제와 다르게 이산적인 값을 가지는 분류 문제에서는 모델의 출력 결과가 로지스틱 함수로 표현된다.
(분류 클래스가 2개인 로지스틱 함수를 클래스가 n개일 때로 확장한 것이 딥러닝에서 주로 사용하는 softmax 함수이다. )

앞단에는 label 뒷단에는 f(x)
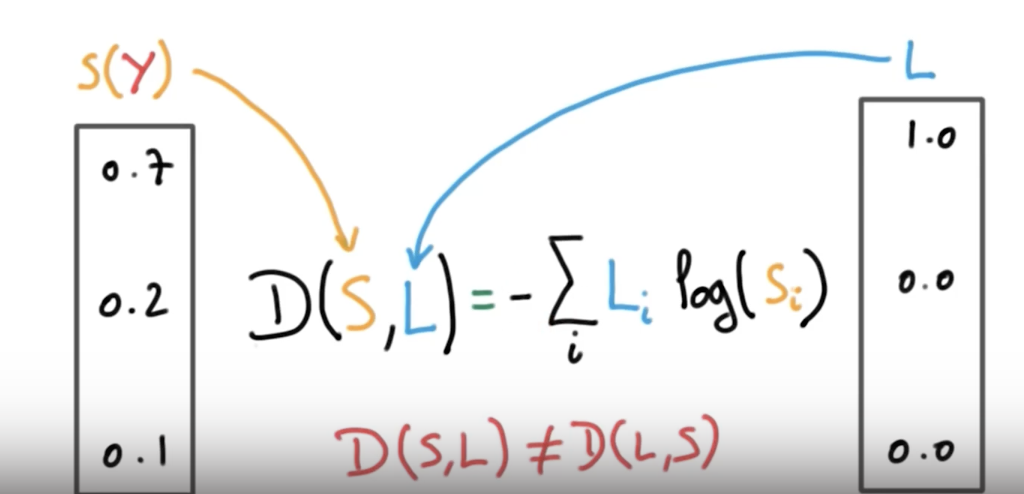
0.7, 0.2, 0.1은 softmax를 통해서 나온 값 ->
0.7에 로그 취한 값 * 1.0 + 0.2에 로그 취한 값 * 0.0 + 0.1에 로그 취한 값 * 0.0
(분류 모델에서 데이터의 라벨은 one-hot encoding을 통해 표현된다. 즉 실제 확률 분포는 원 핫 인코딩으로 표현되는 것이다. 원핫코딩은 클래스의 종류가 N가지이고, 특정 데이터가 n번째 클래스에 속할 때 n번째 원소만 1이고 나머지는 0으로 채운 N차원 벡터로 바꿔주는 것이다. )
: 0일때 이상적인 값이고(딱 맞는다.) 틀릴때 무한대의 값이 나온다.
최종적으로 우리가 인공신경망을 학습시킨다는 것은 Loss function을 0으로 만드는 것이 최종 목적이다.
이를 위해서 가중치와 bias를 찾는다. 찾아가는 방법이 경사 하강법이다.
참고) https://gnoej671.tistory.com/26
5. 객체 지향 프로그래밍
객체
- 데이터(실체)와 그 데이터에 관련되는 동작(절차, 방법, 기능)을 모두 포함한 개념
(속상과 기능을 가지는 프로그램의 단위라고 볼 수 있다. )
- 틀을 만들어둬야한다. (class)를 이용해서 object를 찍어낸다.
객체는 어떻게 정의할까?
class를 통해서! 필드를 미리 결정하고 객체를 형성해서 사용한다.
파이썬에서 형식
class (클래스 이름):
class Person:
def _init_(self,name):
self.name = name
def say_hi(self):
print 'Hello, my name is', self.name
p = Person('Swaroop')
p.say_hi()
6. 상속(Inheritance)

한 클래스에서 가져올 것은 가져오고 값(속성)을 추가해서 사용하고싶을 때
class (클래스 이름)(상속 클래스):
7. numpy
라이브러리임.
import numpy as np
ndarray라는 클래스 많이 사용하는데, 이는 객체이고 Attribute와 Method를 가진다.
List vs ndarray
a = [1,2,3,4,5]
b = [1,2,3,4,5]
a+b
# [1,2,3,4,5,1,2,3,4,5]
for i,j in zip(a,b):
result.append(i+j)
result
# [2,4,6,8,10]
# 곱하기 10을하면 열번 나오고, /10, +1 연산은 수행되지 않는다.
# ------------------------------------------
# 대신 ndarray 사용
import numpy as np
a = np.array([1,2,3,4,5])
b = np.array([1,2,3,4,5])
a + b
# array([2,4,6,8,10])
a*10
# array([10, 20, 30, 40, 50])
a/10
#array[(0.1, 0.2, 0.3, 0.4, 0.5)]: 이를 벡터화 계산이라고한다.
파이썬은 list도 객체임.
* indexing
var[lower:upper:step]
* 음수 사용
0, 1, 2, 3, 4, -> -5, -4, -3, -2, -1
# [10, 11, 12, 13, 14]
a[1:3]
# array([11, 12])
a[1:-2]
# arrary([11, 12])
a[-4:3]
# array([11, 12])
* 다차원

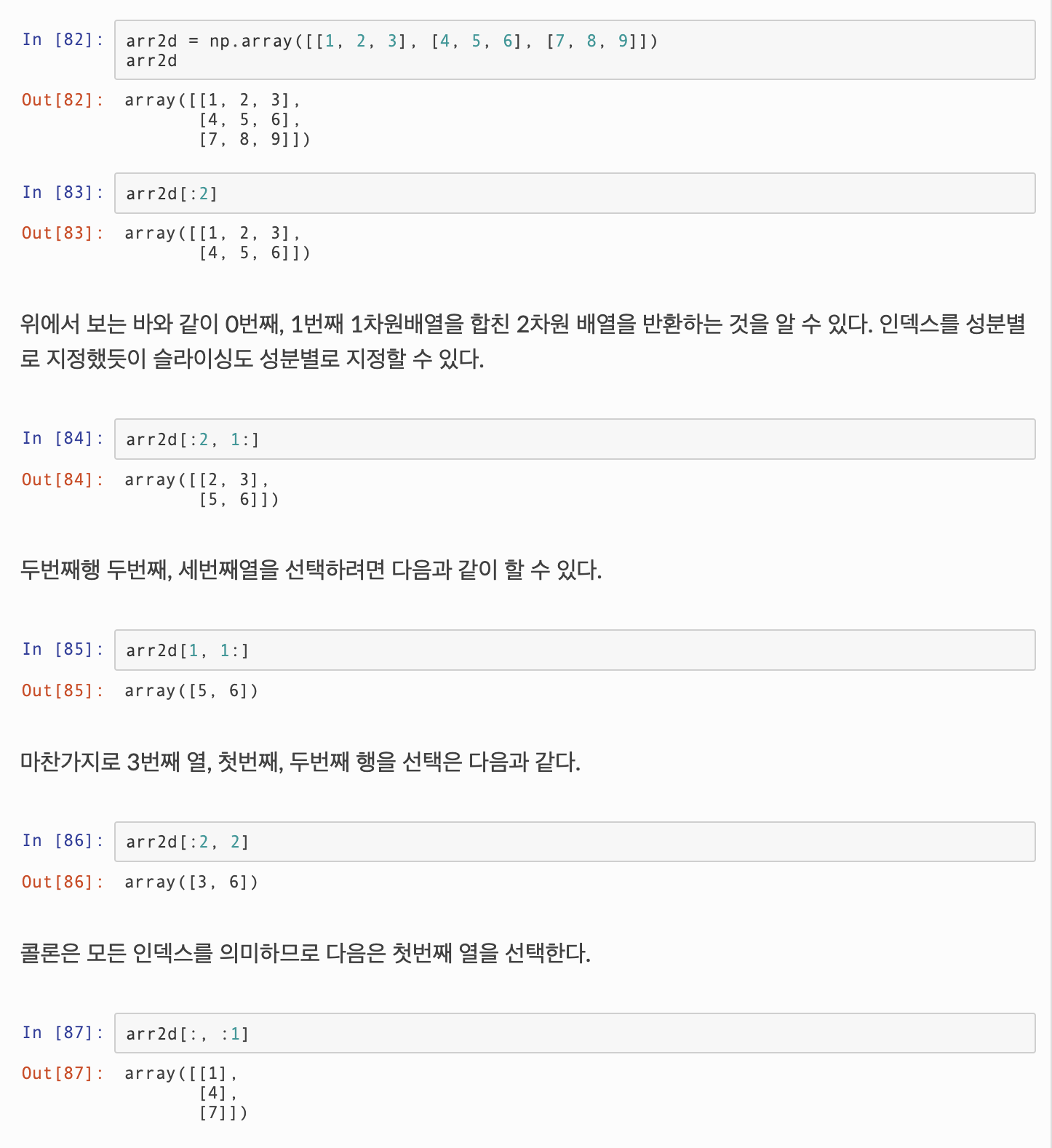
참고 ) https://compmath.korea.ac.kr/appmath/NumpyBasics.html



연산 규칙
1. 고차원 array들의 연산은 shape가 맞는지 확인
2. 기본적인 연산 ex. +, -, *, /, exp 은 원소마다 계산
3. 차원이 줄어드는 연산 (mean, std, sum)은 array 전체에 적용된다. 다만, Axis를 줄 수도 있다.
4. nan의 계산 결과는 nan이다.
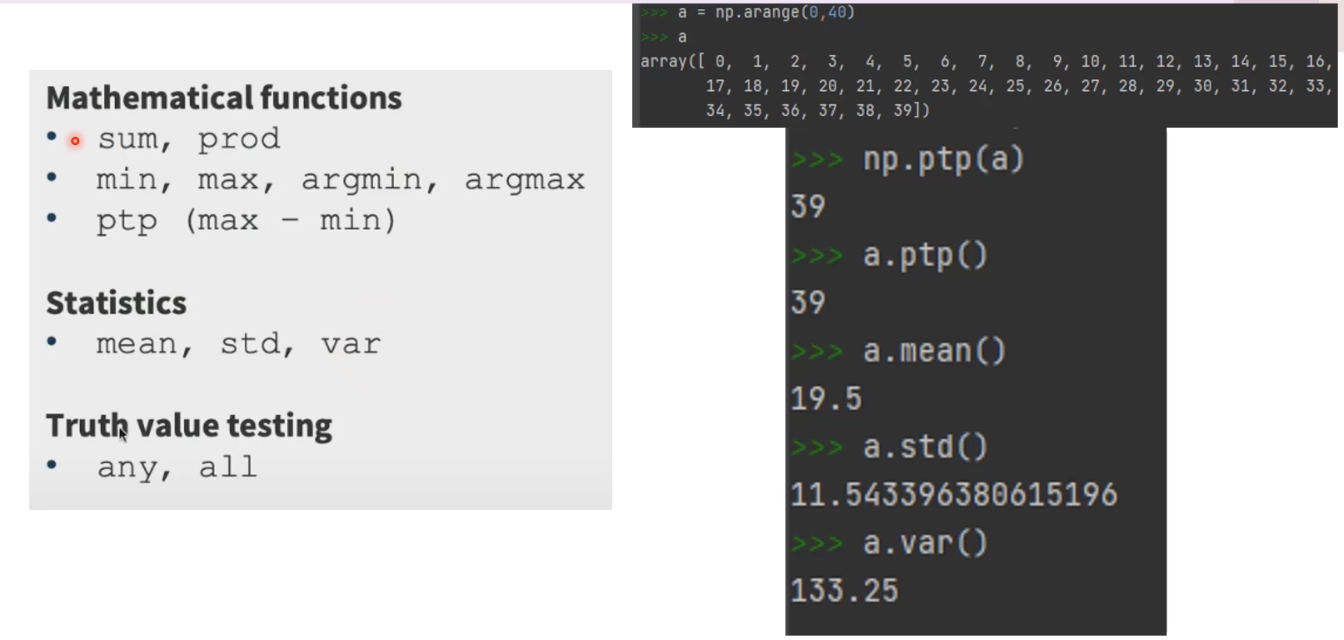
any - 리스트에서 어떤 원소가 있으면 true
all - 리스트에서 모든 원소가 되어야 true
'AI Study > deeplearning, machinelearning' 카테고리의 다른 글
| [ComputerVision] Neural Networks and Backpropogation (0) | 2023.03.27 |
|---|---|
| [DeepLearning] AI 프로그래밍 복습 2 (0) | 2023.03.21 |
| [DeepLearning] 아나콘다, 주피터 가상환경 설정 (0) | 2023.03.12 |


