기본적으로 알아야할 것:
supervised Learning: 정답이 있다. upsupervised Learing: 정답이 없다.
1. Regression
regression은 continous하고 depth estimation 즉 영상의 깊이 정보를 추정한다.
classs는 discrete하고 semantic segmentation 즉 영상을 의미적으로 다른 부분으로 분할한다.
ex.

1-1) regression의 목표
예측: 새로운 input에 대해 ouput을 예측한다.
분석: input과 output의 관계를 설명한다.
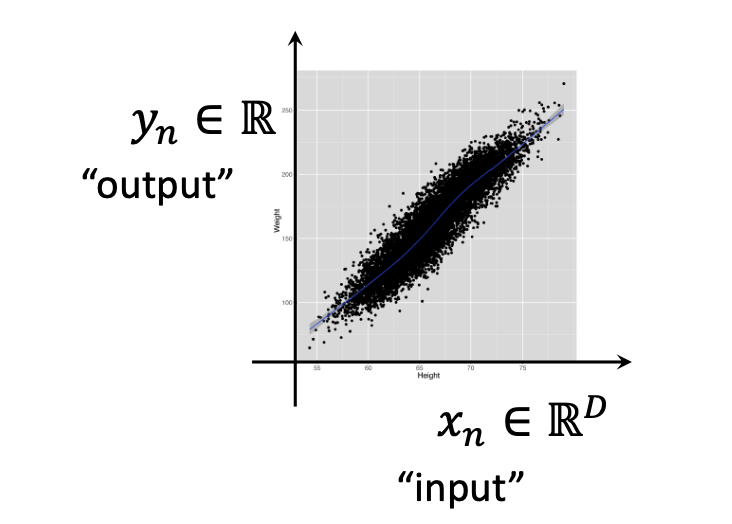
1-2) regression의 데이터 셋
input은 차원이 있는 벡터이고 (D) output은 수이다.
Yn은 n-th output이고, Xn은 벡터 D이다. (여기서 n은 데이터셋의 사이즈이고, D는 차원.)
Input Variables = features, covariates, independent variables, predictors
Output Variables = target, label, response, outcome, dependent variables, measured variable

1-3) Regression Function
regression function의 목표는 mapping function을 찾는 것이다.
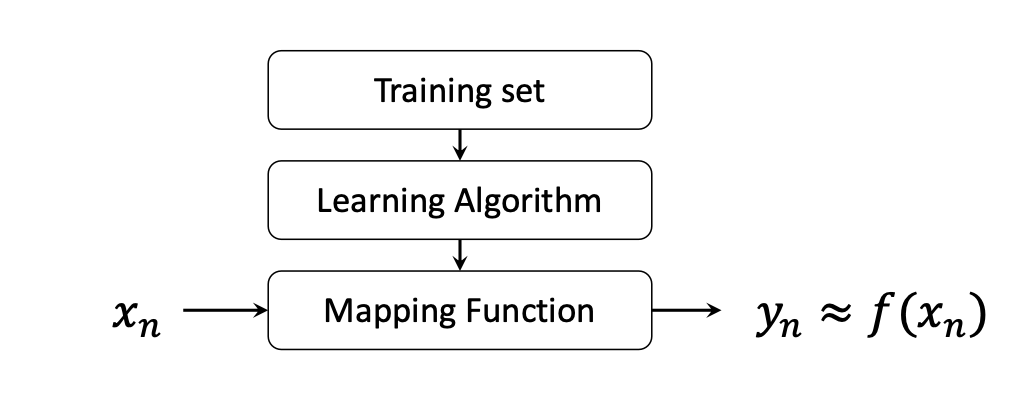
최대한 유사한 y가 나오는 mapping function을 찾는다.
2. Linear Regression
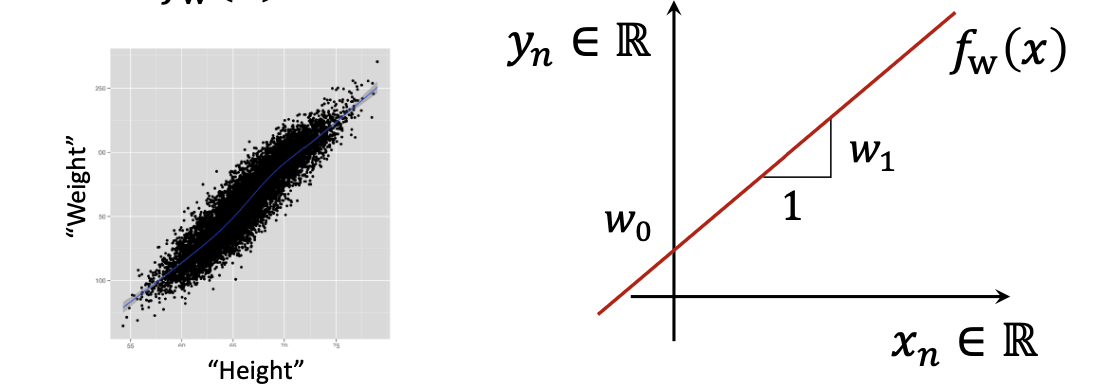
Linear Regression은 선형으로 input과 output의 관계를 표현하는 모델이다.
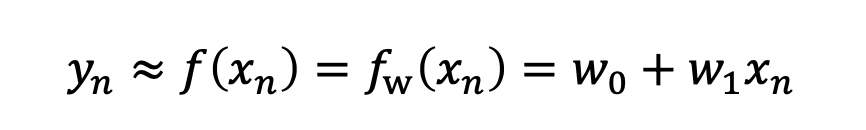
w0, w1 두가지 파라미터를 가진다.
Linear Regression을 사용하는 이유는 simple하고 이해하기 쉽고, 가장 널리 사용되고, non-linear 모델을 쉽게 일반화한다.
하나의 차원에서는 simple linear regression을 가진다.
우리는 parameter W*를 찾아야하는데 이는 learning, estimating the parameters, fitting이라고 불린다.
3. Cost Function (Linear regression)
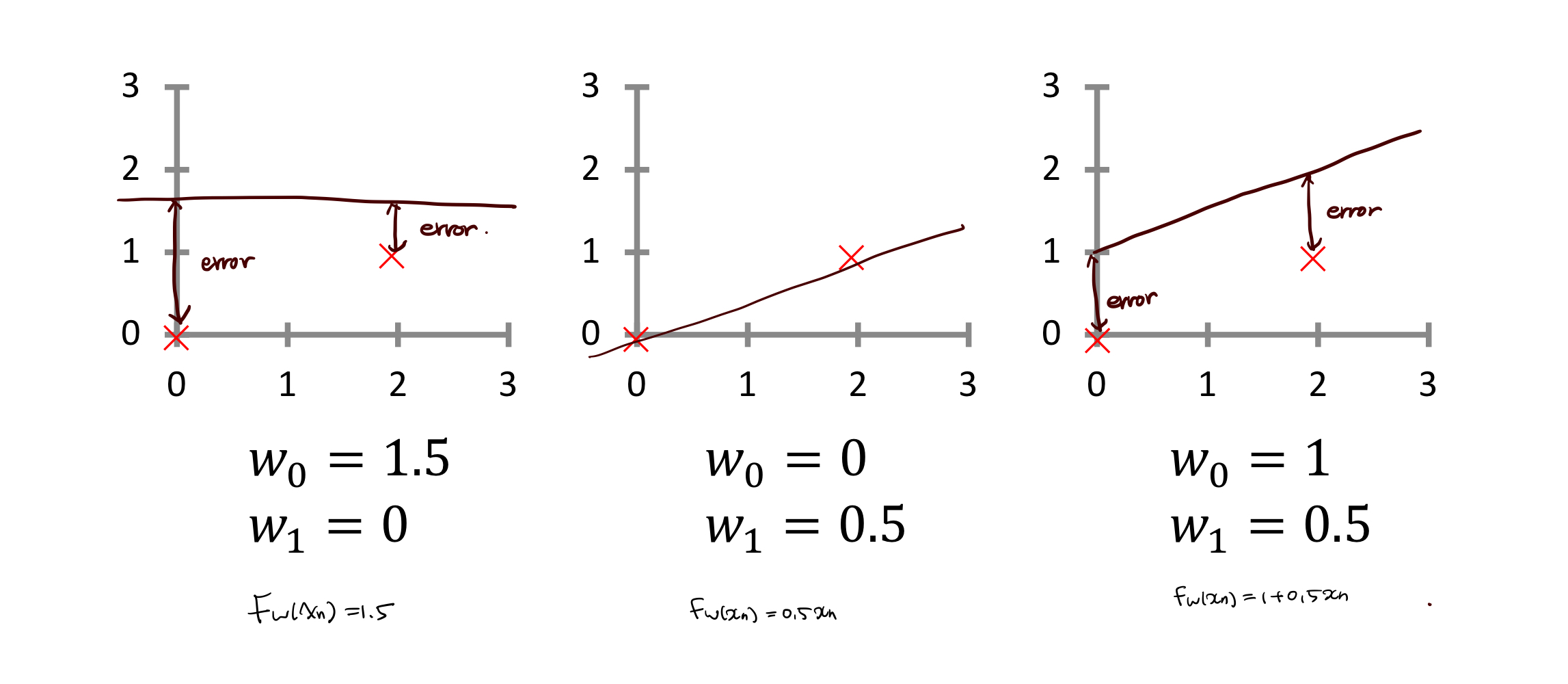
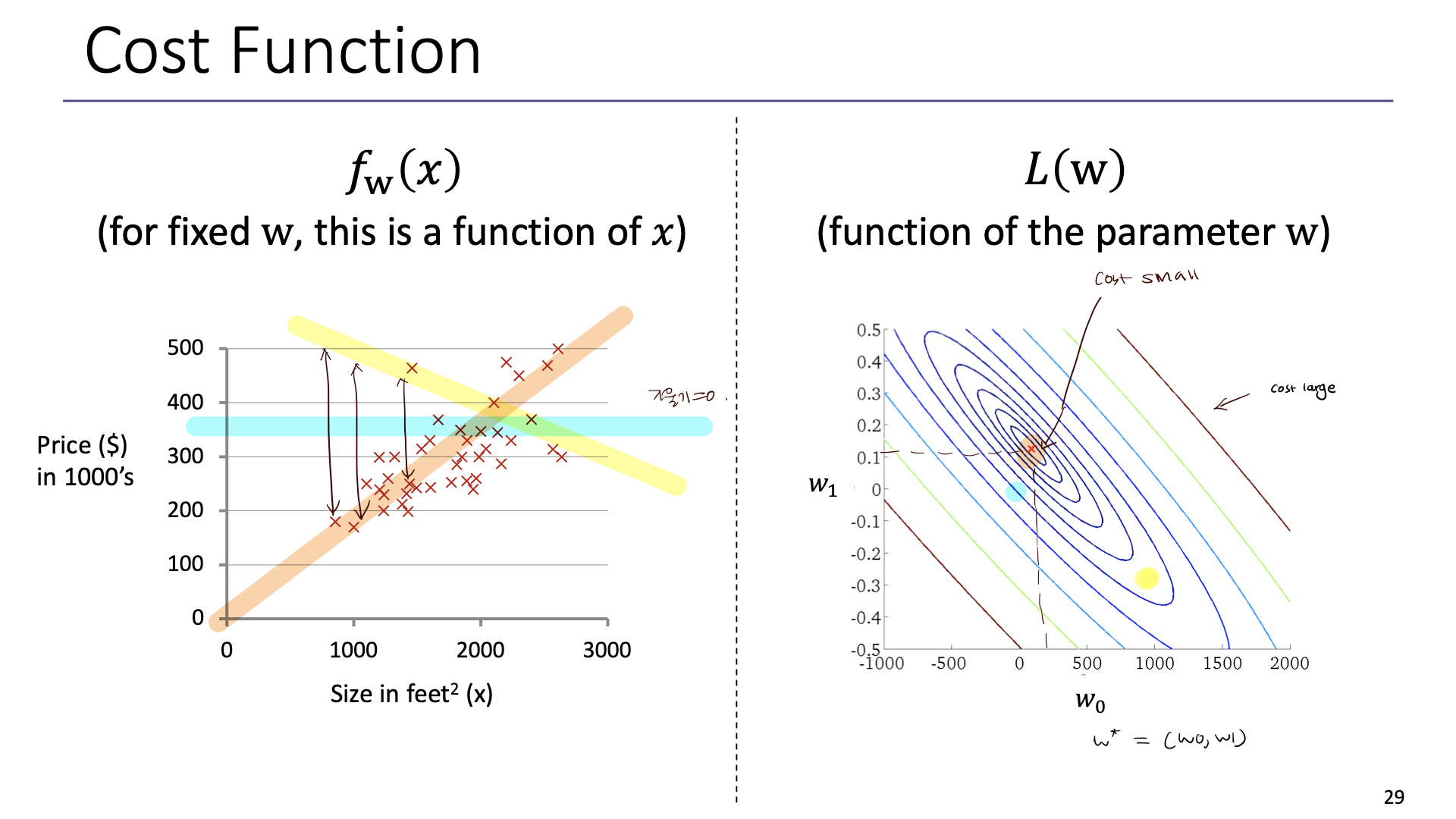
아이디어) W0,W1을 선택할 때 Fx(x)가 y에 가장 근접하는 W를 선택하자.

cost 함수는 모델이 데이터를 얼마나 잘 설명하는지, error를 얼마나 잘 측정하는지를 수량화한다.
예시1) W0=0인 경우

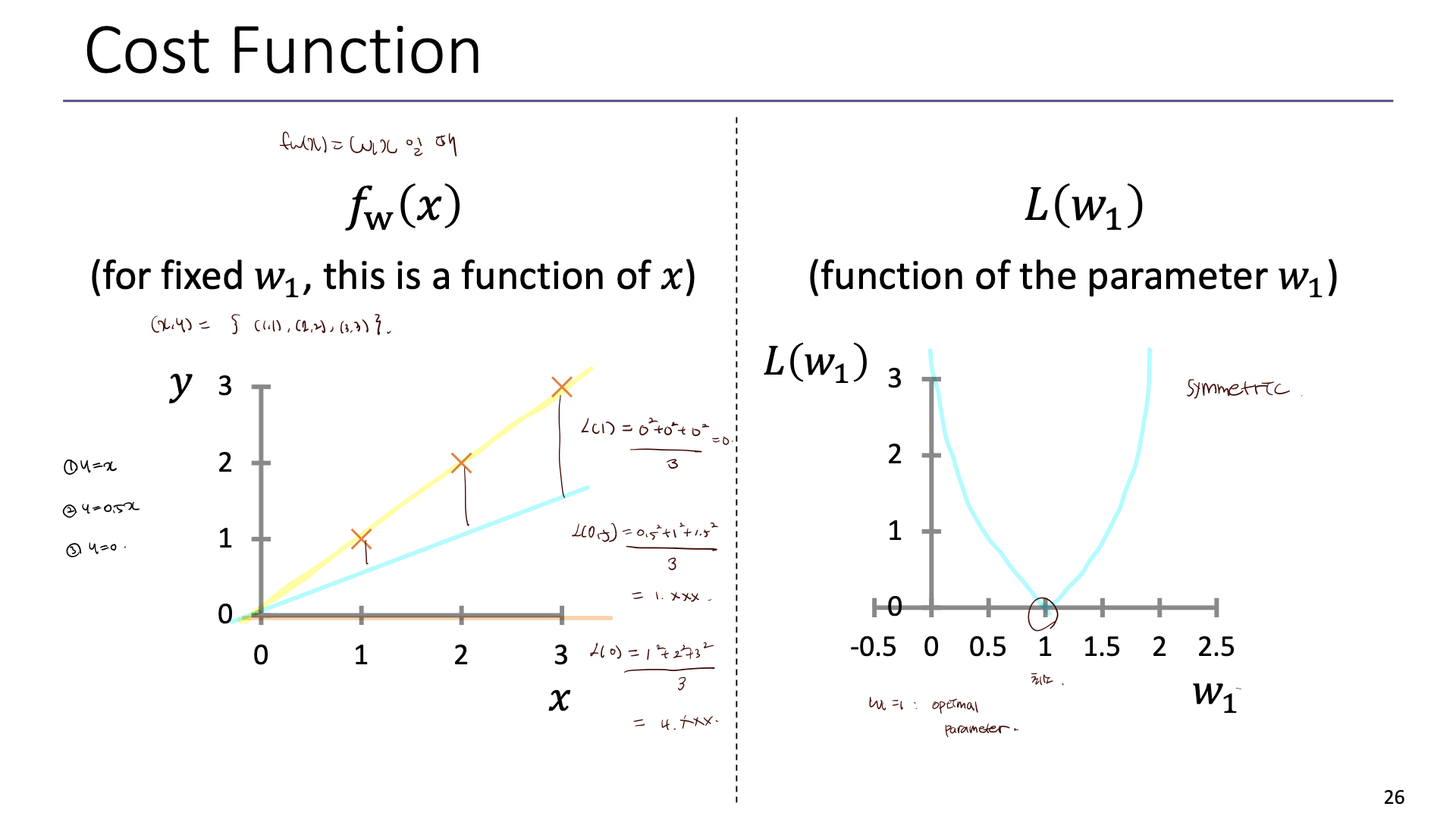
예시 2)

예시) MSE와 MAE

바람직한 case
1. cost는 0을 중심으로 symmetric 한 것이 좋다.
2. large mistake와 very-large mistake에는 동일한 페널티를 주는 것이 좋다. (패널티를 크게 주게 되면 큰 에러를 고치기 위해 파라미터가 잘못 설정될 수 있다.) -> 실제로 모여있는 데이터를 중점으로 설계하는 것이 유리하다.

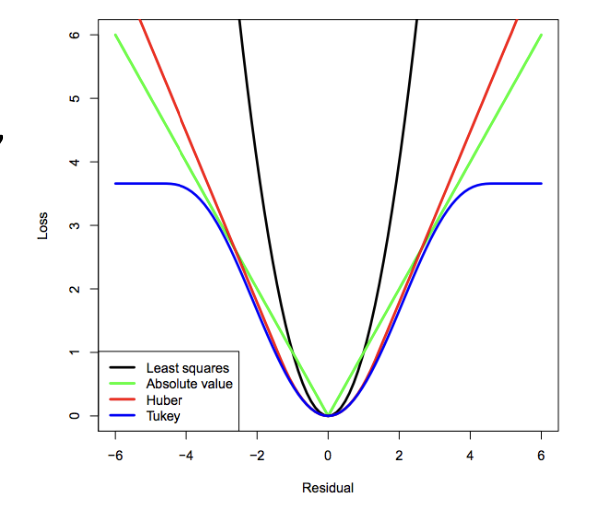
-> 파란색 그래프의 경우 가장 바람직하다. (symmetric 하고 어느정도 error가 커지면 같은 값의 penalty를 부여한다. ) 하지만 computational complexity가 커질 가능성이 있다.
-> 검정색 그래프의 경우 (MSE) error가 커지면 loss 가 기하급수적으로 커지는 경향이 있다.
하지만 MSE는 구현이 편해서 사용하는 경우가 많다.
3. Gradient Descent
최적인 W* 찾기 위함
Grid sesarch - 모든 cost 계산 후 최적 찾는다. brute-force 방식이라 단순하지만 연산량이 많다.
Gradient descent는 낮은 기울기를 찾아가는 것이다. minimum을 찾기 때문에 negative gradient를 찾아간다.
Initial point W=(W0,W1)에서 수정하면서 minimum에 도달하게된다.
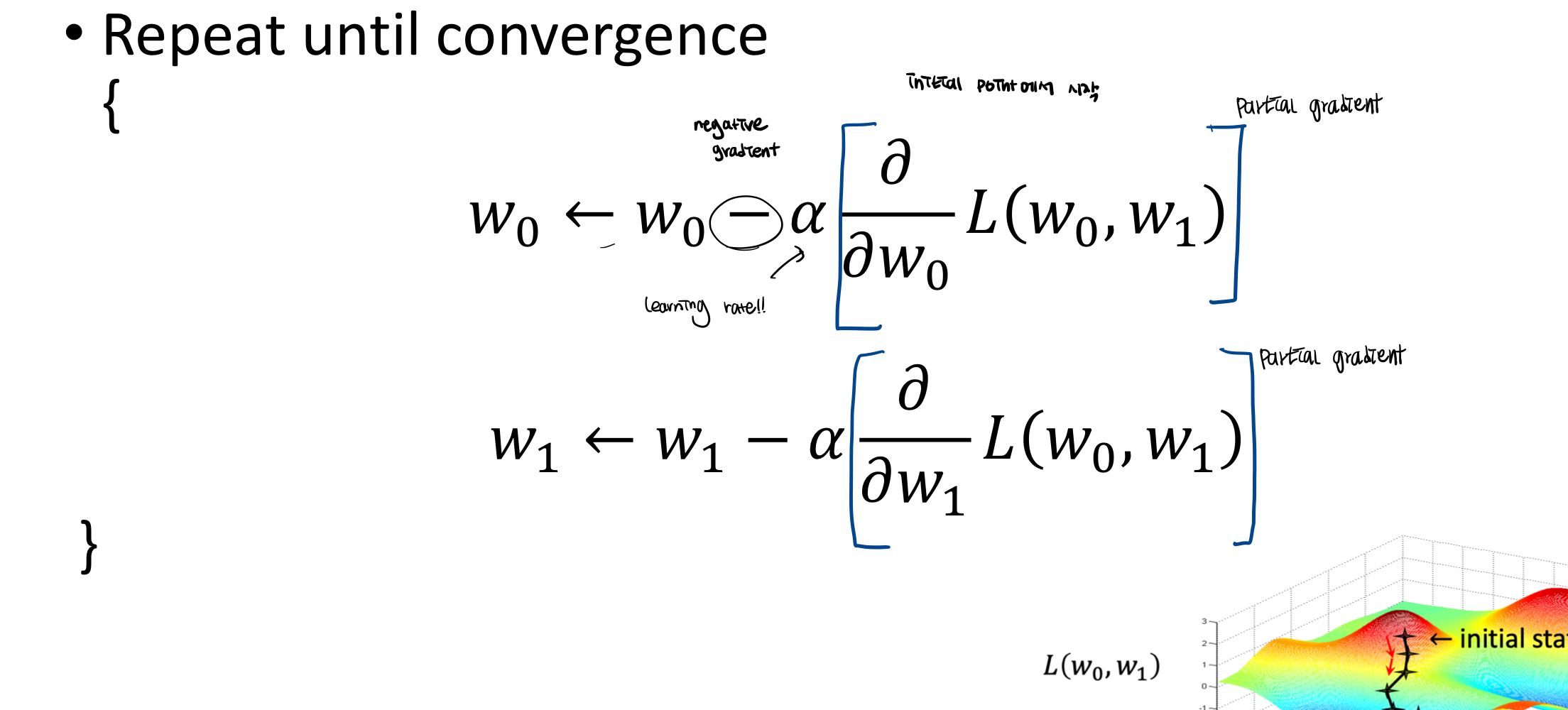
learning rate가 작으면 수렴까지 오래걸리고, 크면 다시 발산할 수도 있다. (적당한 값 찾아야함.)
한계)

4. Multivariate Linear Regression
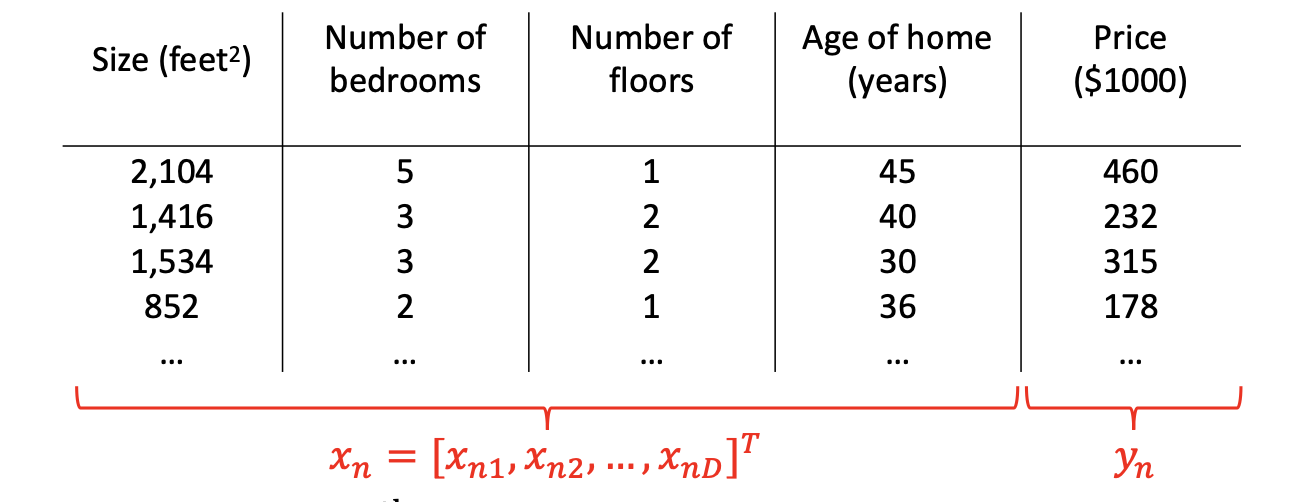
input이 여러개의 값 (D>1)
- Multivariate Linear Regression
D=1 일 때)
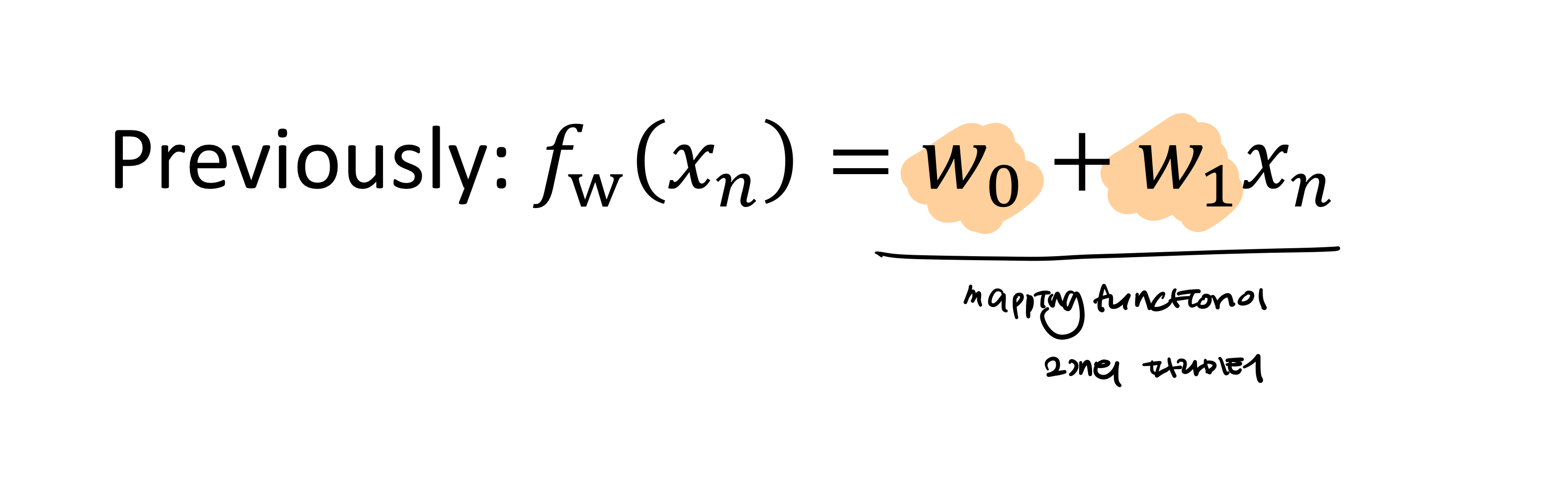
D>1 일 때)
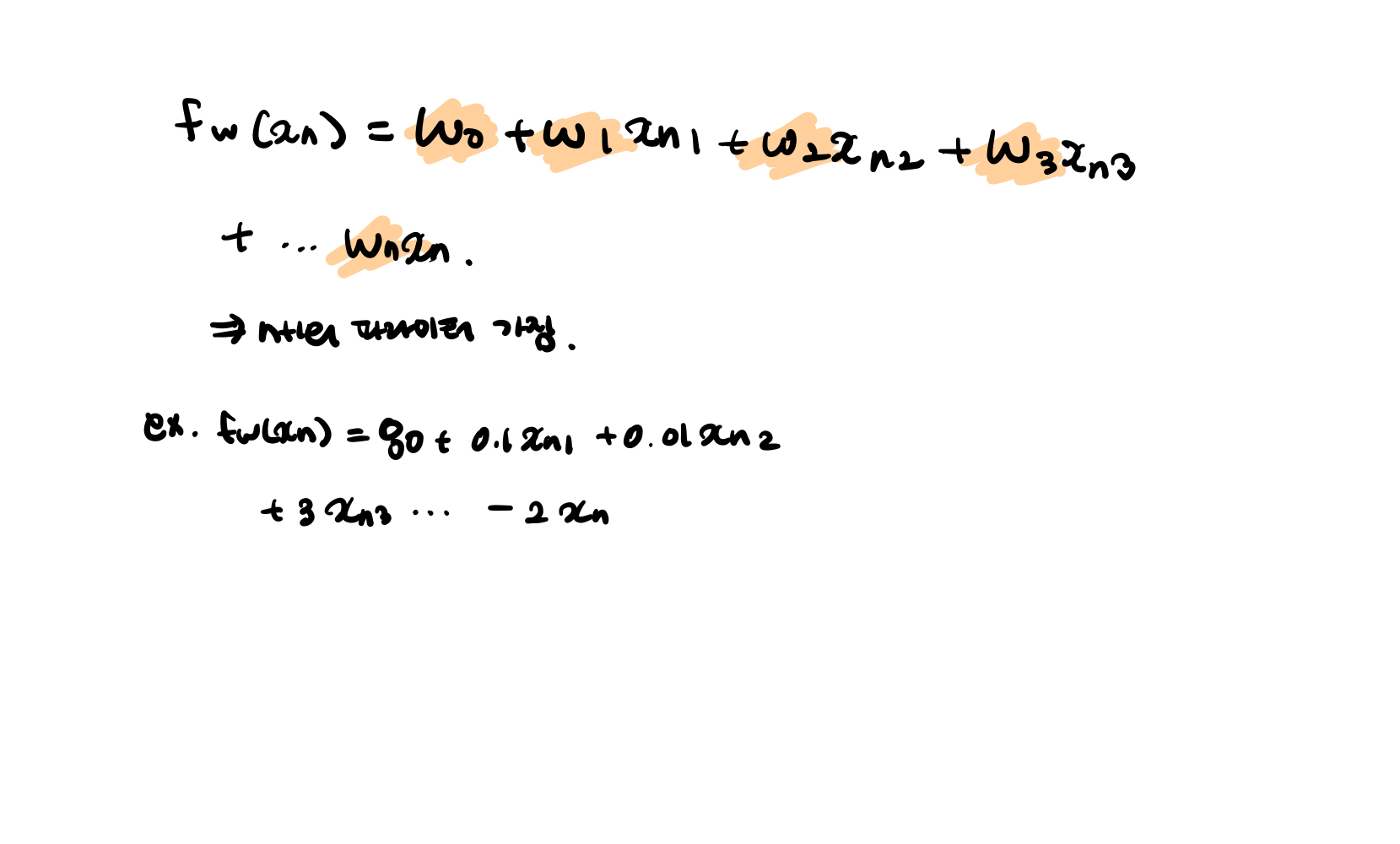
- Multivariate Linear Regression


5. Logistic Regression
classification?
input valuation x to output variable y (y는 카테고리가 있다. = discrete하다.)
ex. 이 이메일은 스팸인가 아닌가?
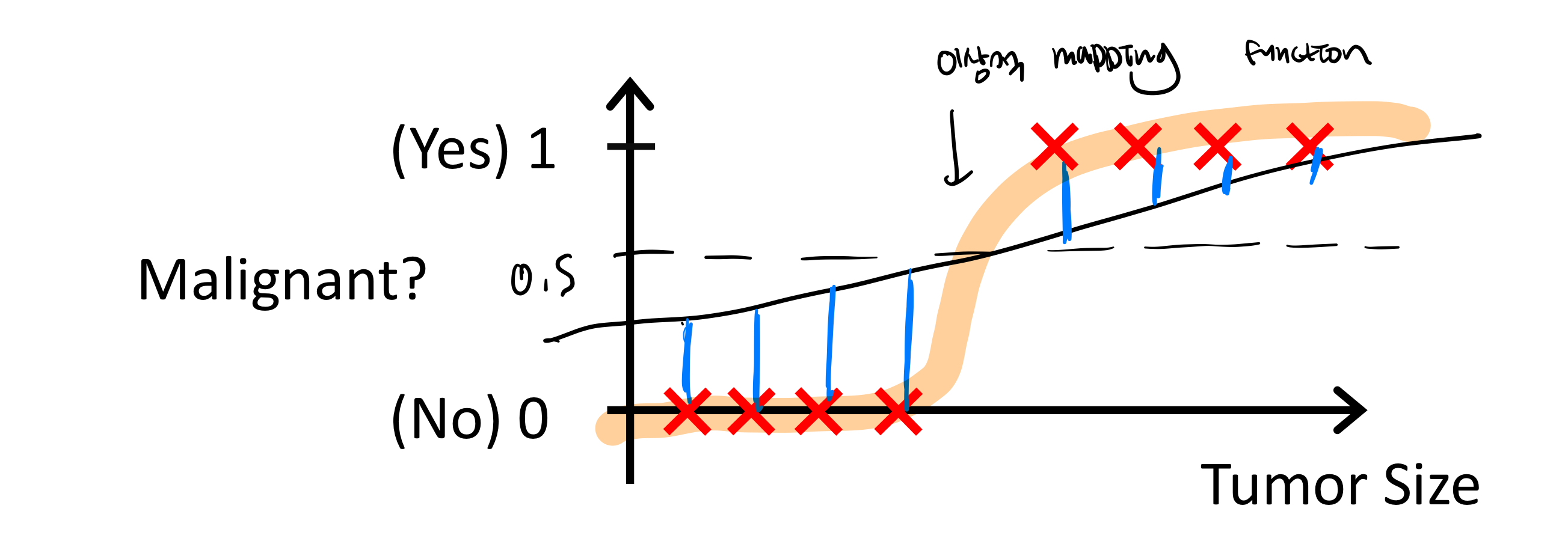
아래 일직선 함수 f(x)로 cost 함수가 정의되면 error가 아래처럼 모두 다른 cost를 가지게된다.
-> classification의 경우 항상 0<y<1 인 값을 가지는 것을 이용하자.
해결

(주황색 그래프, threshold를 설정한다.)

Sigmoid / Logistic Function (=g(z))을 이용해서 mapping function을 설정하자.
(sigmoid 활성화 함수라고 하기도한다.)
기존:
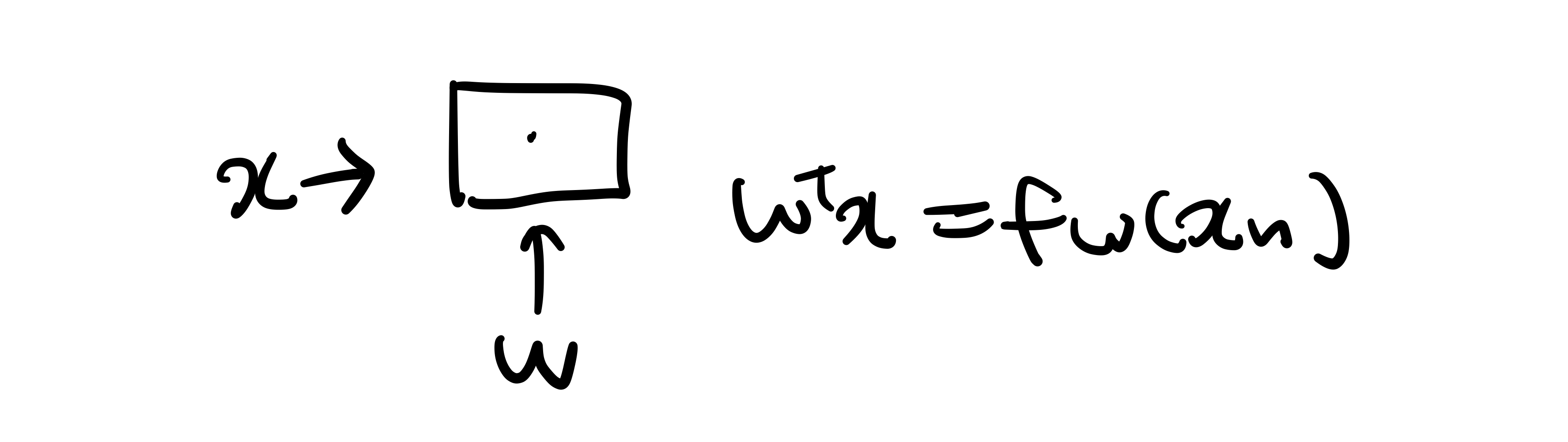
classfication:
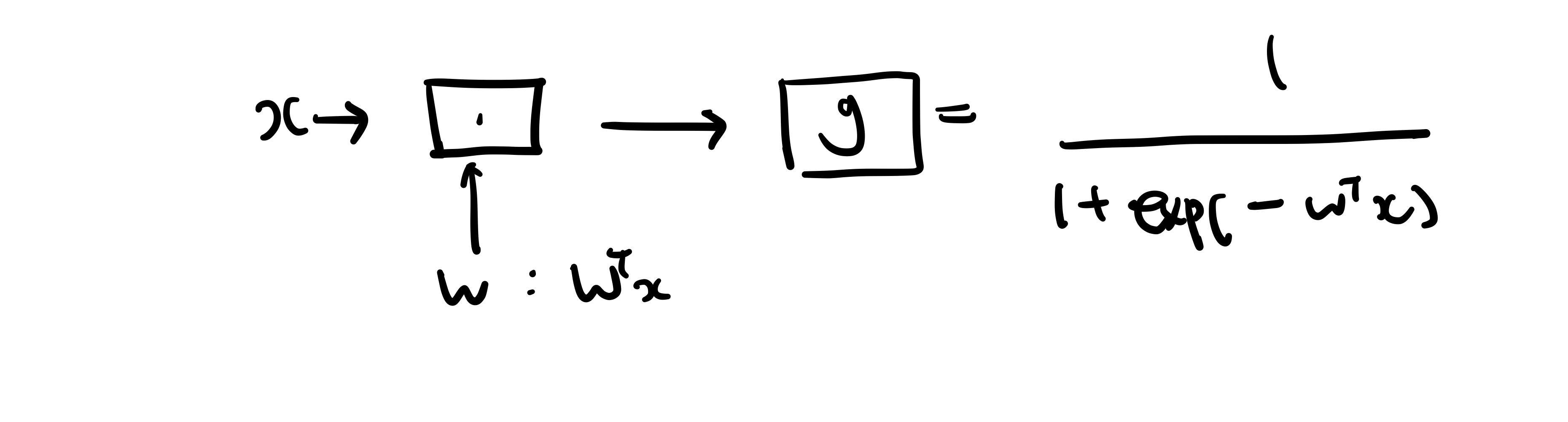
그래서 classification을 logistic regression이라고도 부른다.
- linear Decision Boundary case
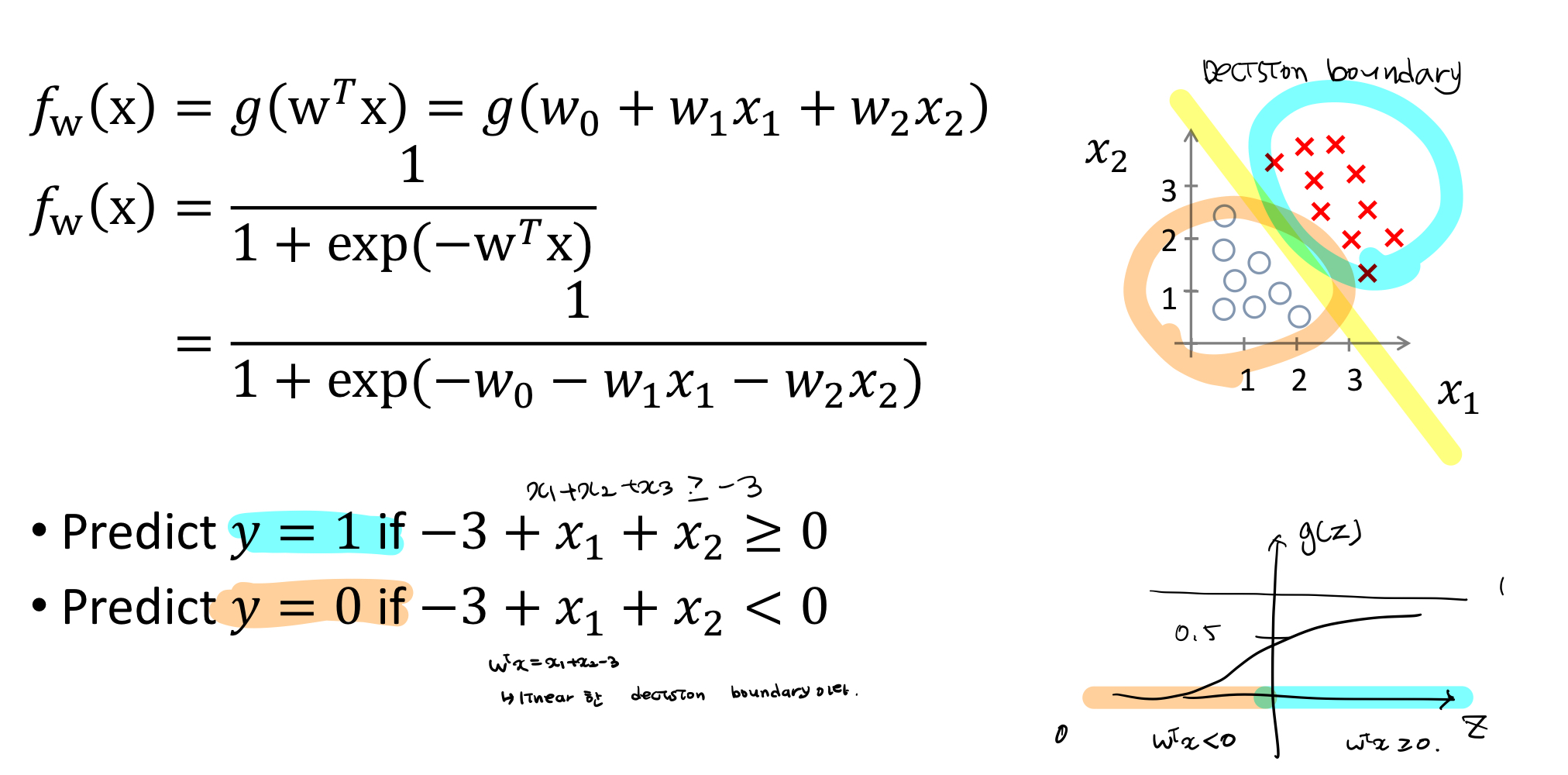
- non-linear Decision Boundary case
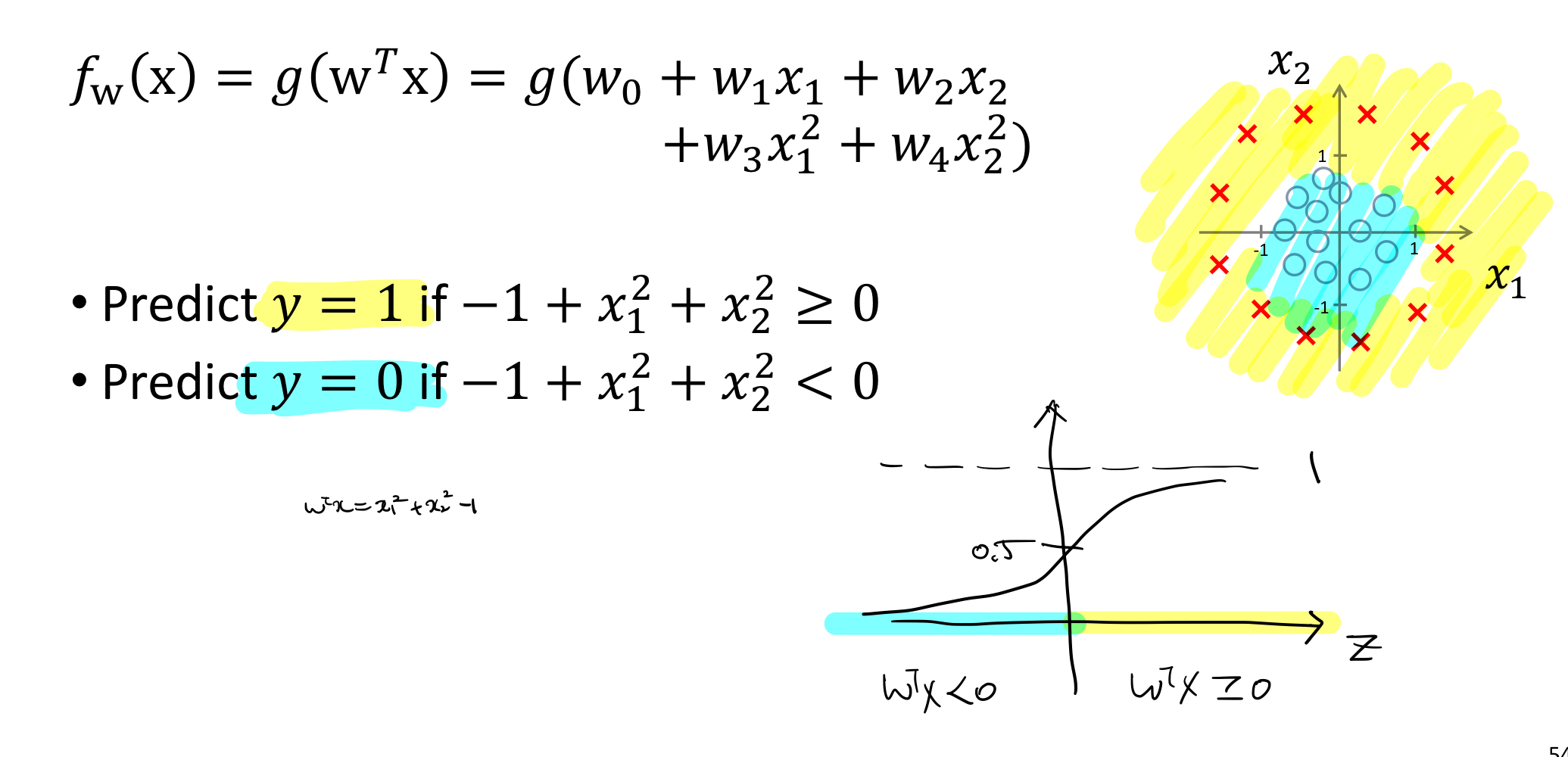
결론:

6. Cost Function (Logistic regression)
linear에서는 주로 MSE 정의 (오른쪽 그래프) 반면 classification에서는 mapping funtion(위 그래프)에 의해서 cost function을 MSE로 했을 때 왼쪽그래프처럼 정의
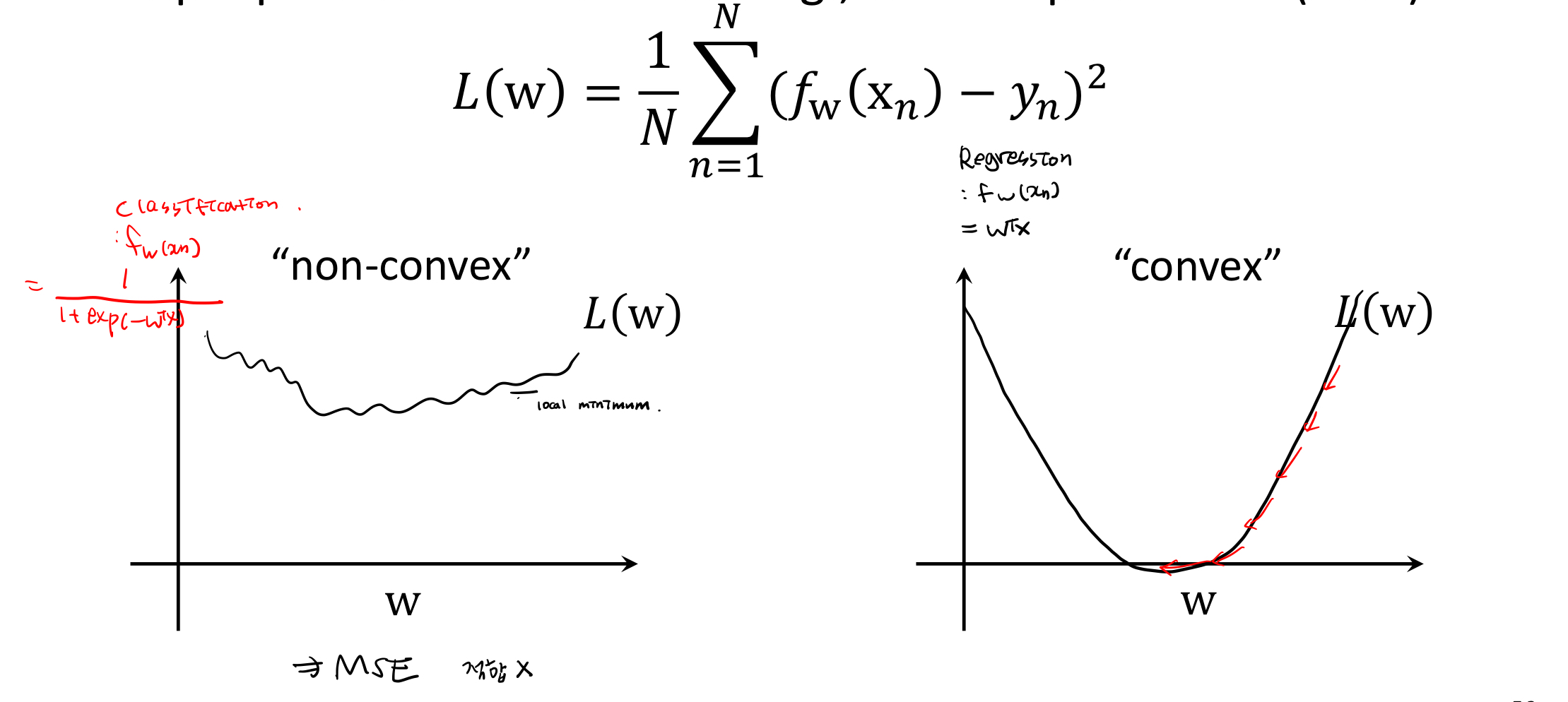
-> local minimum에 빠짐
해결

cost function을 이렇게 많이 정의한다.

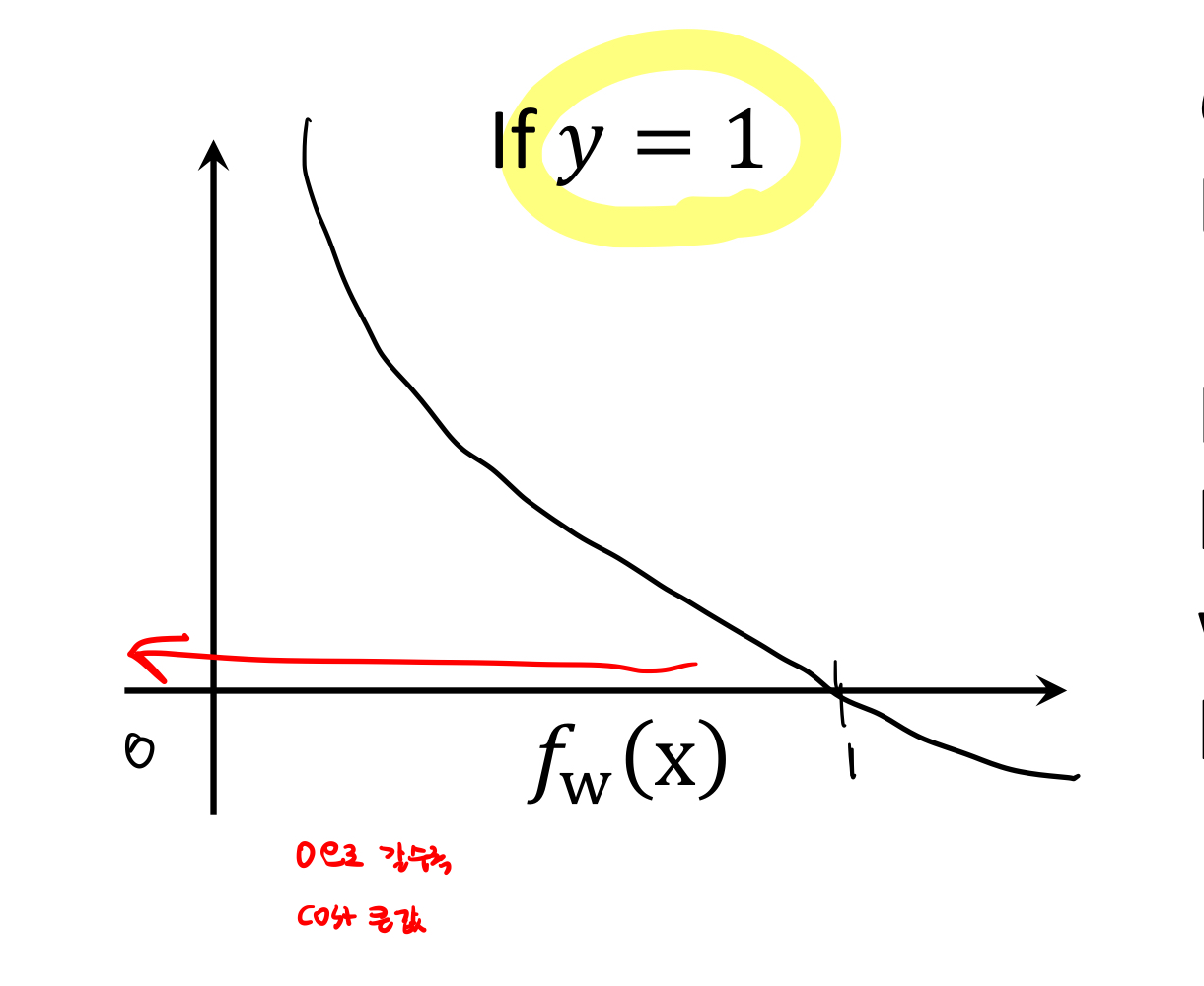

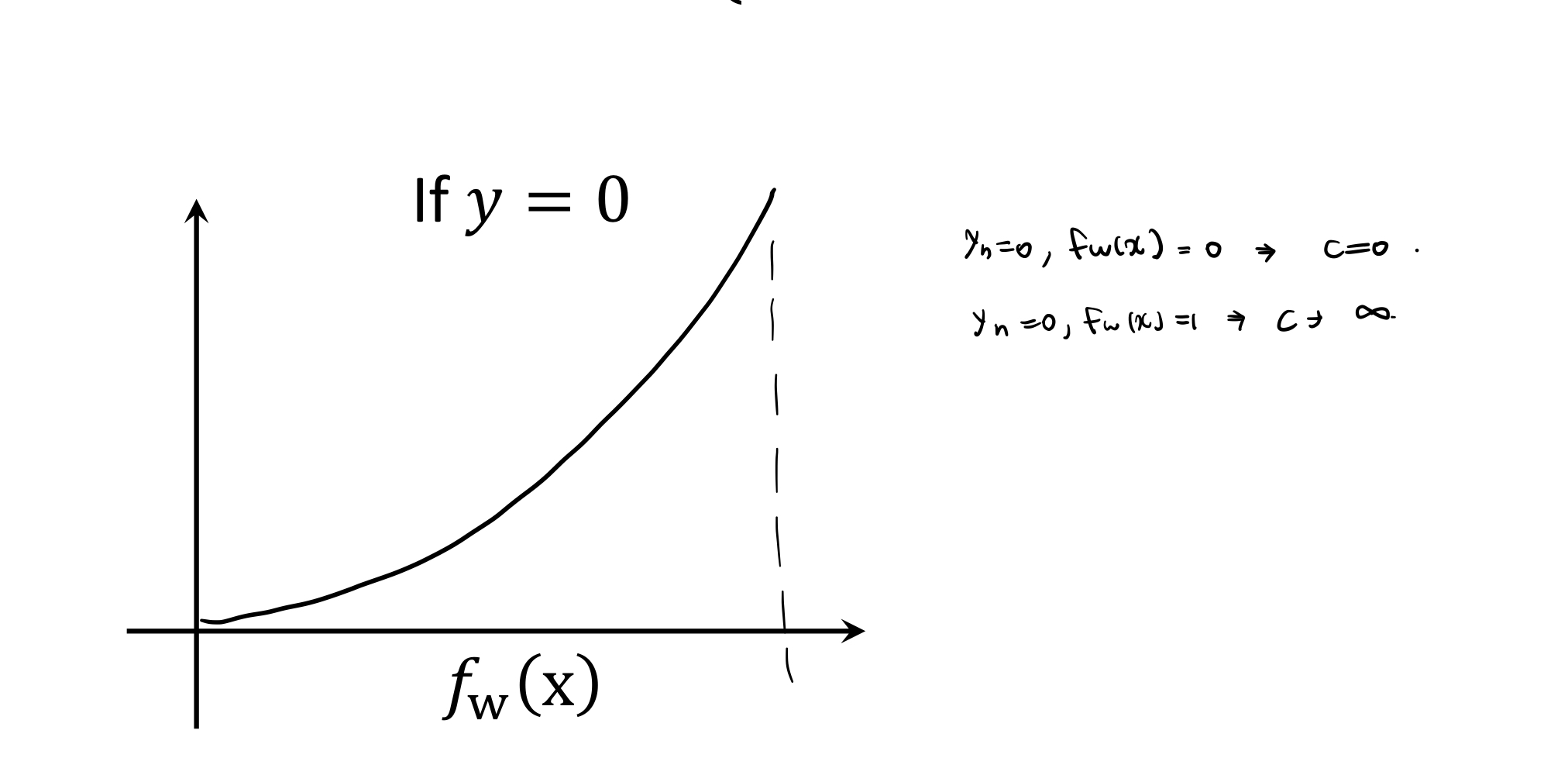
결론
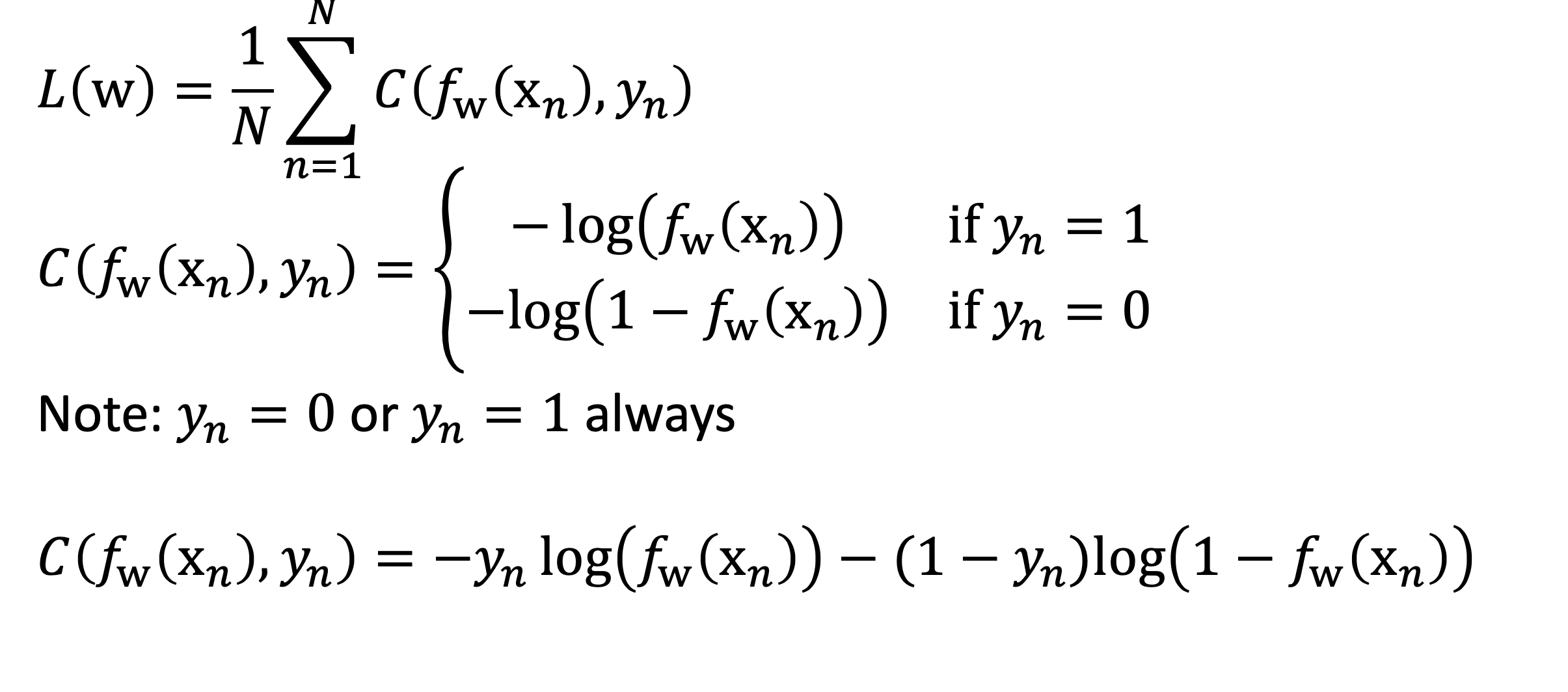


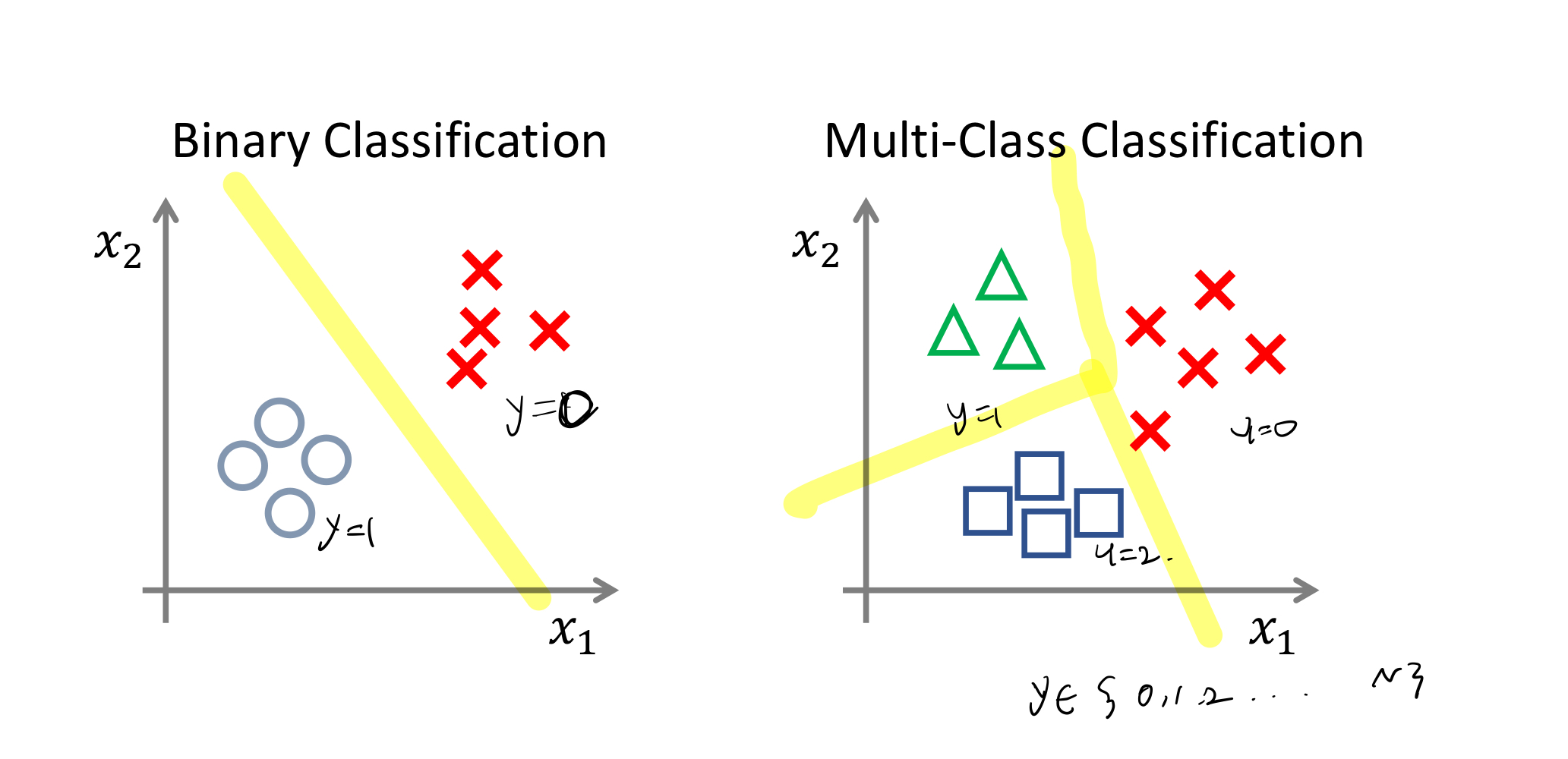
4. Multi-Class Classification
ex. 이메일: Work, Friends, Family, Hobby

'AI Study > computer vision' 카테고리의 다른 글
| [Computer vision] YOLO (You only look once) 모델 (0) | 2023.04.24 |
|---|---|
| [ComputerVision] 공간 도메인과 주파수 도메인 기초 (1) | 2023.03.14 |

