1. YOLO란?
YOLO란 you only look once의 약자로, object detection 분야에서 많이 알려진 모델이다.
2015년에 Joseph Redmon(조셉 레드몬)이 워싱턴 대학에서 2015년도에 yolo v1 버전을 발표했으며 그 당시에 object detection은 대부분 Faster R-CNN이 가장 좋은 성능을 내고있었다. 그가 공개한 YOLO에서 가장 주목을 받았던 점은 객체 감지를 실시간으로 한다는 것이다.

yolo는 처음으로 one-stage-detection 방법을 고안하여 실시간으로 객체 감지를 가능하게 한 모델이다. 기존 Object Detection은 Classification 문제를 2단계로 나눠서 검출하여 정확도는 높지만 여러번 호출함으로써 속도가 느려지는 단점이 있었다. 반면 Yolo는 one-stage 검출기를 이용하여 조금은 정확도가 떨어지지만 빠른 검출기를 만들어냈다.
현재 YOLO, YOLO v2, YOLO v3, YOLO v4, YOLO v5 등의 버전이 있다.
2. YOLO의 특징
- 이미지 전체를 한번만 본다.
yolo는 원본 이미지 그대로를 CNN에 통과시킨다. 이 덕분에 객체 주변 정보까지 학습하여 backgrond error가 적다는 장점이 있다.
- 통합된 모델을 사용한다.
기존에는 region proposal, feature extraction, classification, bBox regression 등의 작업을 별도로 진행했다면, yolo는 한 모델만을 사용해 앞의 과정들을 한 번에 진행한다. 이의 특성 덕분에 이전 모델들에 비해 상대적으로 빠른 속도를 보여준다.
3. YOLO의 동작 과정
1) 사진이 입력되면 가로 세로를 동일한 그리드 영역으로 나눈다.
2) 그리드 영역에 대해서 어디에 사물이 존재하는지 바운딩 박스와 박스에 대한 신뢰도 점수를 예측한다.
3) 이와 동시에 그림 (2)에서와 같이 classification 작업도 진행된다.
4) 굵은 박스들만 남기고 얇은 것들, 즉 사물이 있을 확률이 낮은 것들은 지워준다. (NMS 알고리즘 이용해서 선별)
조금 더 구체적으로 살펴보자! yolo의 신경망을 간단히 표현하면 아래와 같은 단계로 구성되어있다.
결과를 보면 7 X 7 그리드셀 기반의 텐서가 결과값으로 나오고, 각 그리드셀은 길이 30 벡터로 이루어진 텐서이다.
길이가 30인 벡터는 아래 그림과 같이 구성되어있다. 각 그리드 셀마다 예측하는 바운딩 박스는 2개이고, class 개수는 20개로 가정해보자.
첫번째 예측된 바운딩 박스의 정 중앙 좌표인 x,y 바운딩 박스의 너비와 높이를 전체 이미지로 나눠 노멀라이즈한 w,h 그리고 내부 물체가 존재할 확률인 Pc(신뢰도 지수) 이렇게 총 5가지의 아웃풋이 나온다.
위 과정을 한번 더 하면 두 번째 바운딩 박스에 대한 예측값 5개가 나오고 이도 텐서에 넣어준다.
마지막에는 Pr (그리드 셀에 있는 오브젝트가 어떤 클래스인지 확률)이 들어가게 된다. (총 20개의 클래스이므로 20개)
결론적으로 총 길이가 30인 벡터로 이루어진 텐서가 된다.
4. YOLO의 추론 과정
박스의 신뢰도 (Pc)는 Pr(obj) * IOU로 구하고, 각 클래스별 확률값은 Pr(classi | object)로 구한다. 이 둘을 곱해주면 PR(classi) * IoU가 되고, 이는 해당 박스가 특정 클래스일 확률값이 된다.

이를 SxS인덱스에 적용하면 아래 그림과 같다.
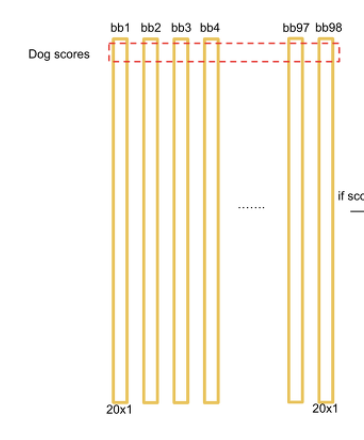
이렇게 구한 벡터들을 모두 모은 뒤 일렬로 나란히 세우면, 각 클래스별로 전체 바운딩 박스에서의 확률값을 구할 수 있다.
다만 각 그리드셀 하나당 2개의 바운딩 박스를 예측함으로써 과도한 바운딩 박스가 감지되는데, 이를 해결하기 위해 Non-max suppression(NMS)을 사용한다.
NMS를 거치면 하나의 바운딩 박스는 하나의 클래스에 속하게되고, 해당하는 클래스의 이미지 위에 박스를 그려주면 된다.
5. Non- max suppression (NMS)
일반적으로 Input image가 object detection 알고리즘을 통과하면 object Bbox가 그려지고, 어떤 물체일 확률값을 가진다. 이때 아래그림처럼 많은 bbox가 그려지는데, 동일한 object에 여러 Bbox가 있다면 가장 스코어가 높은 박스만 남기고 나머지를 제거하는 것이 NMS이다.

NMS는 IOU를 이용한다. IOU는 단순히 설명하면 검출박스 2개의 전체 크기에서 겹치는 비율이 얼마가 되는지를 알아내는 방법이다.

yolo에서 box regression 후 통과한 박스들은 아래 그림과 같은 형태로 나오게 되는데, 연산량이 많아져 느려질 가능성이 크다.

각 cell마다 confidence score이 가장 큰 박스를 고르고 선택한 박스와의 IOU가 임계값보다 큰 박스는 모두 제거한다. 참고로 yolo에서는 defaul가 0.5이다.하나의 박스만 남을 때까지 이를 반복적으로 실행한다.
(구체적인 과정은 아래 링크 참고)
https://deep-learning-study.tistory.com/403
파이썬으로 구현한 NMS
import torch
from IoU import intersection_over_union
def nms(bboxes, iou_threshold, threshold, box_format='corners'):
assert type(bboxes) == list
bboxes = [box for box in bboxes if box[1] > threshold]
bboxes = sorted(bboxes, key=lambda x: x[1], reverse=True)
bboxes_after_nmn = []
while bboxes:
chosen_box = bboxes.pop(0)
bboxes = [box for box in bboxes if box[0] != chosen_box[0] \
or intersection_over_union(torch.tensor(chosen_box[2:]),
torch.tensor(box[2:]),
box_format=box_format)
< iou_threshold]
bboxes_after_nmn.append(chosen_box)
return bboxes_after_nmn
6. Anchor box
위처럼 구현한 YOLO에서는 치명적인 단점을 가지고있다. 하나의 그리드 셀마다 Bounding Box를 하나씩 예측했기 때문에 객체의 크기와 비율에 따라서 예측이 어렵고, 이는 작은 객체나 비율이 다른 객체 예측이 어렵다는 문제가 있다.
이를 해결하기 위해 YOLO v2에서는 Anchor box를 도입하여 해결한다. Anchor box는 미리 정의된 사각형으로, 객체를 감지할 때 각 Anchor box의 크기와 비율을 사용하여 객체를 예측한다. 이는 grid cell이 여러개의 object를 감지할 수 있도록 한다.
Yolo v3에서는 다양한 크기와 비율의 Anchor box를 사용하여 더욱 정확한 객체 감지가 가능해졌다.
7. Yolo의 LossFunction
yolo의 loss는 bBox regression loss, confidence loss, classification loss 이렇게 3가지로 나눌 수 있다.
- bBox Regression loss
grid cell에서 예측한 B개의 바운딩 박스의 좌표 (x, y, width, height)와 Ground Truth 좌표의 오차를 구하는 공식이다.

S²: 시그마 윗부분에 S²에서 S는 (s, s) 즉 feature map의 grid 수이다.
B: 두 번째 시그마 윗부분에서 B는 Anchor Box의 수이다.
첫번째 대괄호 안의 식은 예측한 바운딩 박스의 중심 좌표 x i hat, y i hat과 ground truth 중심 좌표 xi, yi의 오차 제곱을 나타내는 식이다.
두번째 대괄호 식에 width, height도 마찬가지로 오차 제곱으로 나타나있는데 루트가 씌여진 이유는 절대적인 값이 큰 경우 절대적 오류도 커지는 것을 방지하기 위함이다.
앞의 람다는 스케일링을 적용한 것인데, 이는 두 개의 로스들과 균형을 맞추기 위한 밸런싱 파라미터이다.
- object Confidence loss
모든 grid cell에서 예측한 B개의 클래스에 속할 확률값과 GT값의 오차를 구하는 공식이다.
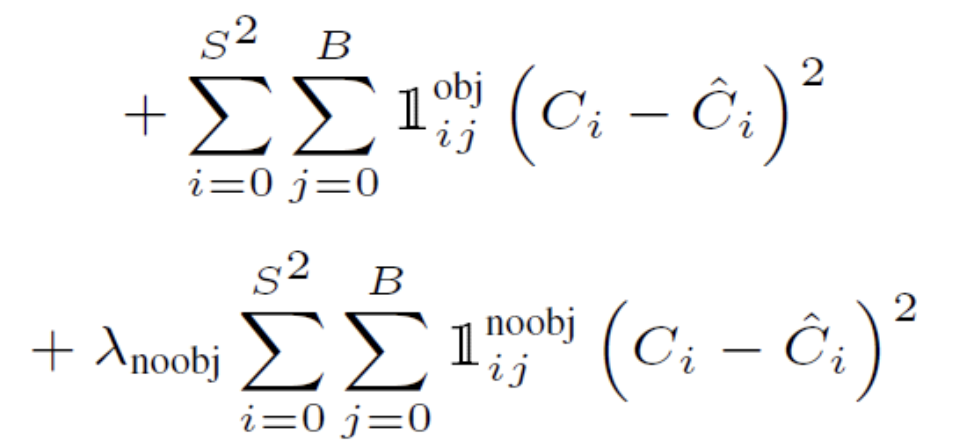
Ci: 모델에서 구한 object일 확률 값에 IOU를 곱한 값이다.
Ci hat: Ground truth confidence score로써 값은 1이다.
두번째 식을 보면 object가 없어야하는 확률에 대해서도 b-box confidence loss를 구해서 포함한다. 다만, 람다 가중치를 곱해주고 있는데, 보통 0.5를 곱해준다. 이는 오브젝트를 포함하지 않을 것인데, 배경에 대해서도 가중을 똑같이 1로 주면 배경 학습에 더 집중할 수 있기 때문에 0.5로 낮춰서 곱해주는 것이다.
- classification loss
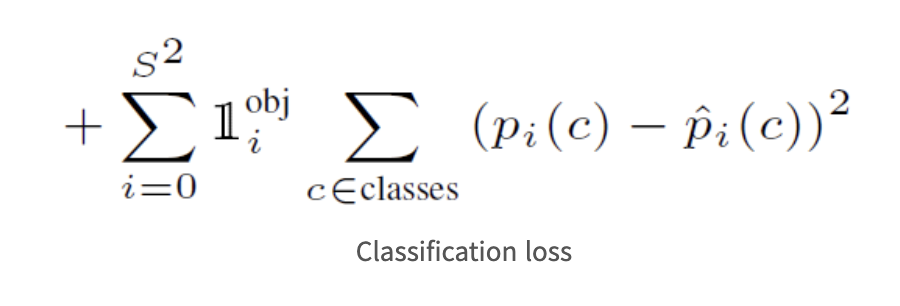
classification loss는 말 그대로 클래스별 확률값에 대한 오차 제곱으로 구해준다.
pi(c): 해당 cell i 내부에 존재하는 object가 c class일 확률이다.
아래는 파이토치로 구현한 yolo 3 모델 코드이다. 직접 돌려보면 큰 도움이 될 것으로 예상된다 : )
https://github.com/csm-kr/yolo_v3_pytorch
GitHub - csm-kr/yolo_v3_pytorch: re-implementation of yolo v3
:blossom: re-implementation of yolo v3 . Contribute to csm-kr/yolo_v3_pytorch development by creating an account on GitHub.
github.com
참고) https://yeomko.tistory.com/19
'AI Study > computer vision' 카테고리의 다른 글
| [ComputerVision] Linear Regression, Logistic Regression (0) | 2023.03.20 |
|---|---|
| [ComputerVision] 공간 도메인과 주파수 도메인 기초 (1) | 2023.03.14 |

